According to the introduction, the latest released state-space models, such as Mamba, have the advantage of establishing long-range dependencies with linear computational complexity, making them very suitable for efficiently processing long sequences of tasks.
Despite Mamba showing good results in fields such as natural language processing and computer vision, its potential in the field of speech separation has not yet been fully explored.
It is understood that speech separation models based on Convolutional Neural Networks (CNNs) are limited by their local receptive field, which restricts their ability to capture the entire context of the audio signal, thereby affecting the separation performance.
Although models based on Transformers can model long-term dependencies very well, their self-attention mechanism has a quadratic complexity relative to the sequence length, resulting in high computational costs in real-time applications.
In summary, existing CNNs, Recurrent Neural Networks (RNNs), and Transformer methods each have their strengths and weaknesses in terms of computational efficiency and capturing temporal dependencies.Based on this, a team from Tsinghua University has proposed a new voice separation model architecture called SPMamba, ingeniously integrating Mamba into voice processing, thereby successfully introducing State Space Models (SSMs) into the field of voice separation.
Advertisement
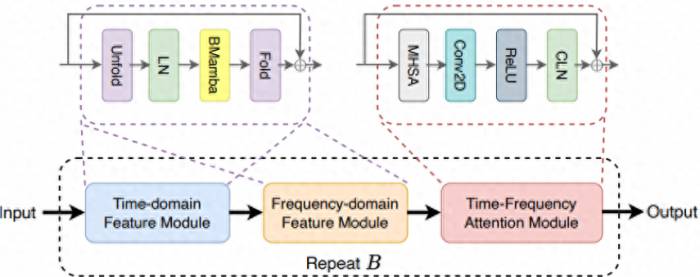
SPMamba is based on TF-GridNet, using a bidirectional Mamba module to replace the Transformer component, aiming to significantly enhance the model's ability to understand and process the vast context of audio sequences.
This can overcome the limitations of CNN models in processing long audio sequences and the inherent low computational efficiency of RNN models.
Through this study, the research team aims to explore the potential of state space models, especially Mamba, in voice separation tasks, with the hope of designing a computationally efficient and high-performance voice separation model architecture.
At the same time, it also hopes to promote further research and development of audio processing models based on state space models.The speech separation model SPMamba, based on the state-space model, can achieve better separation performance with lower complexity and is more suitable for long audio processing.
It is reported that the model can efficiently and accurately separate the speech of different speakers from mixed voice signals, providing technical support for applications such as intelligent voice assistants and voice conference systems.
By enhancing speech clarity and intelligibility through SPMamba, the performance of these systems in noisy environments and user experience can be greatly improved.
At the same time, due to its ability to better handle long audio, SPMamba can be used for audio-visual content creation, such as automatically separating dialogues, background music, and other elements from videos, facilitating post-production editing and processing.
In addition, speech separation technology also has important application value in fields such as criminal investigation and court trials, assisting in the analysis and restoration of voice evidence at the scene of the case.The SPMamba model's high separation accuracy and computational efficiency advantages make it extremely promising for development in these practical application scenarios.
At the same time, this achievement also provides new methods for other speech processing tasks such as speech enhancement and speech recognition.
Researchers stated: "We initially determined this research direction after discovering that the state-space model named Mamba in the field of natural language processing performed exceptionally well in handling long-sequence tasks, with efficiency and performance superior to other models."
In fact, the research team had previously attempted to apply another state-space model, S4, to speech separation and proposed the S4M model.
Experimental results also confirmed the advantages of the state-space model in this field, and the relevant paper has been published in Interspeech 2023.On this basis, they hope to explore whether Mamba can also be used to construct an efficient and high-performance model in the field of speech separation, and apply it to the processing of long sequence speech separation.
Then, they began to experiment on the dataset. "This dataset is one that we have constructed to be more in line with the current real-world scenario, and this dataset will also be released later," the research team added.
During the experiment, the research team focused on the TF-GridNet model, which is a model that has achieved state-of-the-art performance in the field of speech separation.
TF-GridNet has excellent modeling capabilities in both the time domain and frequency domain, and it is very robust against interference factors such as noise and reverberation.
The excellent performance of TF-GridNet led the team to decide to take it as the basis to explore how to further improve the effect of speech separation.Subsequently, they discovered that Mamba is a causal model, meaning that without such models, it is impossible to obtain information about the future.
The speech separation task they are currently researching happens to require the assistance of future information to enhance the model's performance.
Thus, they began to introduce the bidirectional Mamba module into the TF-GridNet framework. In this framework, the Mamba module is responsible for capturing the long-term dependencies of the speech signal.
Considering the historical and future information contained in the speech signal, the research team designed a bidirectional structure to fully model the context of the speech sequence.
This bidirectional structure shares a similar advantage with bidirectional LSTM (BLSTM, bi-directional long short-term memory), but the former has higher computational efficiency.The evaluation results on the dataset demonstrate that SPMamba's performance is exceptionally outstanding. Compared to TF-GridNet, the former has achieved a 2.42dB improvement in the SI-SNRi metric, showcasing the immense potential of incorporating state-space models into speech separation.
Recently, the related paper was published on arXiv[1] with the title "SPMAMBA: STATE-SPACE MODEL IS ALL YOU NEED IN SPEECH SEPARATION."
Li Kai, a master's student at Tsinghua University, is the first author, and Chen Guo, also a master's student at Tsinghua University, is the co-first author.
Before the paper was published on arXiv, the team decided to release the code a week in advance.
"Unexpectedly, this move attracted the attention of many researchers, who came to inquire about technical details and discuss the innovative aspects of the model," the team stated.In addition, when the researchers attended the International Conference on Acoustics, Speech and Signal Processing (ICASSP) in South Korea in 2024, many domestic and international peers specifically sought out this team to discuss the SPMamba model.
"When I see my work being recognized, everyone's research enthusiasm is also ignited, and I also feel a heartfelt comfort and pride. At that moment, I truly realized the significance of being a scientific researcher," said the researchers.
Based on the outstanding performance of SPMamba in the speech separation task, they plan to further explore and expand the application range of the model.
Firstly, the research team will conduct experiments and tests on more public datasets to comprehensively evaluate the generalization ability and robustness of SPMamba.
This will help to verify the model's performance under different scenarios and data conditions, providing more reliable references for practical applications.Next, the team plans to explore the field of music, particularly testing the ability of SPMamba to handle long-sequence audio on the MUSDB18-HQ dataset.
Musical signals typically have longer durations and more complex structures, which pose higher demands on the model's modeling capabilities.
Experiments on the music separation task will further explore the potential of SPMamba in capturing long-term dependencies.
In addition, they will also consider applying SPMamba to other related tasks, such as speech enhancement and speaker extraction.
It is understood that speech enhancement aims to extract clear speech from noisy environments, while speaker extraction focuses on separating the voice of the target speaker from mixed speech.These tasks share similar characteristics with voice separation, hence SPMamba is expected to achieve equally impressive performance in these areas.
In general, they are committed to validating the effectiveness of the model on more datasets and tasks, by continuously optimizing the model structure, with the hope of achieving new breakthroughs in a broader field of audio processing.
